
Реляционная модель данных¶
Этот документ является переводом части лекции Майка Байера (Michael Bayer) о SQLAlchemy, которая была представлена на Pycon 2013.
Реляционная модель¶
Модель представляет собой фиксированную структуру математических понятий, которая описывает то, как будут представлены данные. Базовой единицей данных в пределах реляционной модели является таблица.
Таблица¶
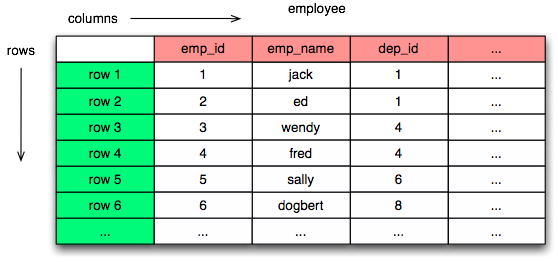
Таблица - это базовая единица данных. В реляционной алгебре она называется «отношение» (relation). Состоит из столбцов (columns), которые определяют конкретные типы данных. Данные в таблице организованы в строки (rows), которые содержат множества значений столбцов.
Язык описания данных (DDL)¶
В SQL для создания таблицы используется оператор CREATE TABLE. Этот оператор является примером языка описания данных (DDL). DDL служит для описания структуры базы данных. Пример использования:
CREATE TABLE employee (
emp_name VARCHAR(30),
dep_id INTEGER
)Первичные ключи¶
При создании таблицы могут быть использованы различные «ограничения» (constraints), которые содержат правила, указывающие, какие данные представлены в ней. Одним из самых используемых ограничений является первичный ключ (primary key constraint), который гарантирует, что каждая строка таблицы должна содержать уникальное значение. Первичный ключ может состоять из одного или нескольких столбцов. Первичные ключ, состоящие из нескольких столбцов, также называются «составными» (composite).
Правильным считается наличие первичного ключа во всех таблицах базы данных. При этом существует два варианта первичных ключей: искусственный (surrogate primary key) и естественный (natural primary key).
Первый вариант обычно представляет собой целочисленный идентификатор. Применяется там где нет возможности использовать натуральный первичный ключ. Позволяют решать те же практические задачи, что и естественные: улучшение производительности памяти и индексов при операциях обновления.
Второй же вариант представляет собой данные, которые уже присутствуют в описываемой предметной области. Например, почтовые индексы могут быть использованы как естественные первичные ключи без дополнительной обработки. Их использование, если, конечно, оно возможно, считается более правильным, чем искусственных.
Пример создания первичного ключа:
CREATE TABLE employee (
emp_id INTEGER,
emp_name VARCHAR(30),
dep_id INTEGER,
PRIMARY KEY (emp_id)
)Внешние ключи¶
В то время как одна таблица имеет первичный ключ, другая таблица может иметь ограничение, описывающее, что её строки ссылаются на гарантированно существующие строки в первой таблице. Это реализуется через создание в «удалённой» таблице («потомке») столбца (может быть и несколько), значениями которого являются значения первичного ключа из «локальной» таблицы («родителя»). Вместе наборы этих столбцов составляют внешний ключ (foreign key constraint), который является механизмом базы данных, гарантирующим что значения в «удалённых» столбцах присутствуют как первичные ключи в «локальных». Это ограничение контролирует все операции на этих таблицах: добавление / изменение данных в «удалённой» таблице; удаление / изменение данных в «родительской» таблице. Внешний ключ проверяет, чтобы данные корректно присутствовали в обоих таблицах. Иначе операции будут отменены.
Внешние ключи могут быть составными, если входящие в них первичные ключи являются таковыми.
В примере представлена таблица «department», которая связана с таблицей «employee» через отношение столбцов «employee.dep_id» и «department.dep_id»:

Представленная на рисунке связь может быть описана через DDL следующим образом:
CREATE TABLE department (
dep_id INTEGER,
dep_name VARCHAR(30),
PRIMARY KEY (dep_id)
)
CREATE TABLE employee (
emp_id INTEGER,
emp_name VARCHAR(30),
dep_id INTEGER,
PRIMARY KEY (emp_id),
FOREIGN KEY (dep_id)
REFERENCES department(dep_id)
)Нормализация¶
Реляционная модель базируется на реляционной алгебре, одним из ключевых понятий которой является нормализация.
Основной идея нормализации в исключении повторяющихся данных так, чтобы конкретная часть данных была представлена только в одном месте. Этот подход позволяет упростить данные до максимально атомарного вида, с которым намного проще работать: искать, производить какие-либо операции.
Классический пример денормализованных данных:
| name | language | department |
|---|---|---|
| Dilbert | C++ | Systems |
| Dilbert | Java | Systems |
| Wally | Python | Engineering |
| Wendy | Scala | Engineering |
| Wendy | Java | Engineering |
Строки в этой таблице могут быть уникально идентифицированы по столбцам «name» и «language», которые являются потенциальным ключом. По теории нормализации таблица из примера нарушает вторую нормальную форму. Потому как неосновной атрибут «department» логически связан только со столбцом «name». Правильная нормализация в данном случае выглядит следующим образом:
| name | department |
|---|---|
| Dilbert | Systems |
| Wally | Engineering |
| Wendy | Engineering |
| name | language |
|---|---|
| Dilbert | C++ |
| Dilbert | Java |
| Wally | Python |
| Wendy | Scala |
| Wendy | Java |
Теперь наглядно видно, как вторая форма улучшила структуру данных. Изначально пример содержал повторы связок полей «name» и «department» так часто, как часто встречался уникальный для данного имени «язык». Улучшенный же вариант сделал связки «name/department» и «name/language» независимыми друг от друга.
Ограничения данных, такие как первичные и внешние ключи, предназначены как раз для достижения состояния нормализации. Для примера выше это будет выглядеть так:
- «Employee Department -> name» - первичный ключ;
- «Employee Language -> name, language» - составной первичный ключ;
- «Employee Language -> name», в свою очередь, - внешний ключ, на поле «Employee Department -> name».
Если таблицу удаётся сходу свернуть в отношения ключей, то это, зачастую, значит, что она не нормализована.
Язык управления данными (DML)¶
После того как определена схема базы данных и таблиц, в них можно помещать данные и изменять их с помощью DML, который реализован частью конструкций SQL. Далее будут подробно разобраны основные из этих конструкций.
Вставка (insert)¶
Новые строки добавляются с помощью команды INSERT. Эта команда содержит часть VALUES, в которой прописаны данные для каждой добавляемой строки:
INSERT INTO employee (emp_id, emp_name, dep_id)
VALUES (1, 'dilbert', 1);
INSERT INTO employee (emp_id, emp_name, dep_id)
VALUES (2, 'wally', 1);Автоинкрементные целочисленные ключи
Большинство современных баз данных содержит в себе функционал для генерации инкрементных целочисленных значений, которые обычно используются в качестве искусственных первичных ключей. Как в примере с таблицами «employee» и «department». Например, при использовании SQLite, столбец emp_id в коде выше будет автоматически создан целочисленным; при использовании MySQL для создания автоинкрементных ключей используется опция AUTO INCREMENT; в PostgreSQL для этих целей служит тип данных SERIAL. Когда используются генераторы автоинкрементных первичных ключей, можно опустить эти столбцы в команде INSERT:
INSERT INTO employee (emp_name, dep_id)
VALUES ('dilbert', 1);
INSERT INTO employee (emp_name, dep_id)
VALUES ('wally', 1);Базы данных с этой функциональностью также позволяют получить сгенерированное при вставке значение. При этом используются нестандартные для SQL конструкции и / или функции. Например, в PostgreSQL это параметр RETURNING:
INSERT INTO employee (emp_name, dep_id)
VALUES ('dilbert', 1) RETURNING emp_id;| emp_id |
|---|
| 1 |
Обновление (Update)¶
Команда UPDATE служит для изменения данных в существующих строках, использую параметр WHERE для фильтрации строк по какому-либо условию и параметр SET для установки нового значения в нужный столбец:
UPDATE employee SET dep_id=7 WHERE emp_name='dilbert'Когда команда UPDATE выполняется по условию, как в примере выше, в результате может быть изменено любое количество строк. В том числе и ни одна. Обычно присутствует некоторый счётчик строк, который позволяет получить информацию о том, сколько строк было отфильтровано и, как следствие, изменено.
Удаление (Delete)¶
Команда DELETE служит для удаления строк. Также как и UPDATE использует параметр WHERE для выборки нужных строк:
DELETE FROM employee WHERE dep_id=1Запросы (Queries)¶
Ключевой особенностью SQL является возможность построения запросов к данным. Для этого используется команда SELECT. Также как и в командах UPDATE и DELETE в ней присутствует параметр WHERE.
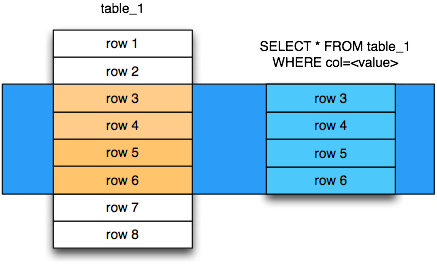
Например, можно выбрать строки у которых dep_id равен 12:
SELECT emp_id, emp_name FROM employee WHERE dep_id=12Команда SELECT из примера выше имеет следующие части:
- Параметр FROM указывает таблицы, из которых выбираются строки.
- Параметр WHERE используется для фильтрации выбираемых строк по какому-либо условию.
- Между словами SELECT и FROM расположен список столбцов, которые необходимо показать из каждой отфильтрованной строки.
Результат примера может выглядеть как-то так:
| emp_id | emp_name |
|---|---|
| 1 | wally |
| 2 | dilbert |
| 5 | wendy |
Сортировка¶
К команде SELECT можно добавить параметр ORDER BY задающий по какому полю сортировать результаты:
SELECT emp_id, emp_name FROM employee WHERE dep_id=12 ORDER BY emp_name| emp_id | emp_name |
|---|---|
| 2 | dilbert |
| 1 | wally |
| 5 | wendy |
Объединения (Joins)¶
Запросы могут использовать механизм объединений для строк из двух таблиц и представления их как одна строка. Обычно объединение производится по внешним ключам.
Параметр JOIN помещается внутри блока FROM, между именами объединяемых таблиц. Он, в свою очередь, в себе содержит параметр ON, который отвечает за критерий объединения строк из разных таблиц.
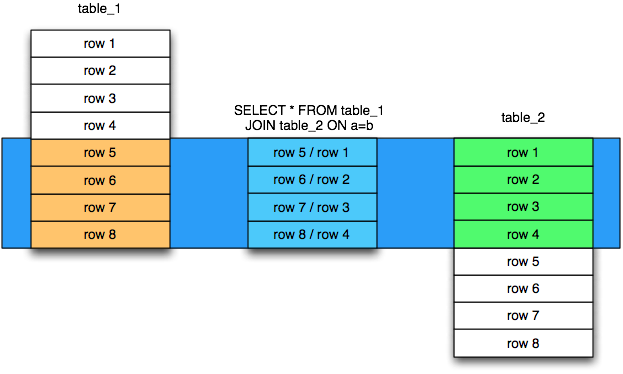
JOIN создаёт промежуточную структуру табличного вида. Она содержит в себе объединенные данные из обоих таблиц.
Используя примеры с таблицами Department и Employee, выберем сотрудников вместе с названиями их отделов:
SELECT e.emp_id, e.emp_name, d.dep_name
FROM employee AS e
JOIN department AS d
ON e.dep_id=d.dep_id
WHERE d.dep_name = 'Software Artistry'| emp_id | emp_name | dep_name |
|---|---|---|
| 2 | dilbert | Software Artistry |
| 1 | wally | Software Artistry |
| 5 | wendy | Software Artistry |
Левое внешнее объединение (Left Outer Join)¶
Этот вид объединения позволяет вернуть строки из «левой» части даже в том случае, если у них нет соответствия в «правой». Например, если мы хотим выбрать отделы и их сотрудников, дополнительно, получить названия отделов без сотрудников, то необходимо использовать конструкцию LEFT OUTER JOIN:
SELECT d.dep_name, e.emp_name
FROM department AS d
LEFT OUTER JOIN employee AS e
ON d.dep_id=e.dep_idДопустим наша компания имеет три отдела, из которых отдел «Sales» на данный момент не имеет сотрудников. В этом случае результаты могут выглядеть следующим образом:
| dep_name | emp_name |
|---|---|
| Management | dogbert |
| Management | boss |
| Software Artistry | dilbert |
| Software Artistry | wally |
| Software Artistry | wendy |
| Sales | <NULL> |
Также существует «right outer join», который использует «правую» часть, как основную. Но использование этой конструкции считается не очень элегантным шагом.
Агрегация¶
Функция агрегации принимает на вход множество значений, выдавая на выходе одно. Наиболее часто используемая функция агрегации - это``count()``. Она получает набор строк и возвращает их количество.
В качестве параметра может использоваться любое SQL выражение. Наиболее часто используется шаблон *, означающий «все столбцы». В отличии от большинства функций агрегации count() не вычисляет значение своего аргумента, а просто считает сколько раз он был вызван:
SELECT count(*) FROM employee| count |
|---|
| 18 |
Другая функция агрегации может вернуть нам среднее количество сотрудников в офисах. Для этого нам также потребуется использовать конструкцию GROUP BY в подзапросе:
SELECT avg(emp_count) FROM
(SELECT count(*) AS emp_count
FROM employee GROUP BY dep_id) AS emp_counts| count |
|---|
| 2 |
Примечание
Запрос в этом примере производит подсчёт только по отделам, в которых есть сотрудники. Для включения в расчёты отделы без сотрудников нужно использовать более сложный подзапрос.
Группировка¶
Конструкция GROUP BY, применяемая в выражении SELECT, служит для группировки результатов по какому-либо полю. Она зачастую используется совместно с агрегацией для применения агрегирующей функции к каждой из групп.
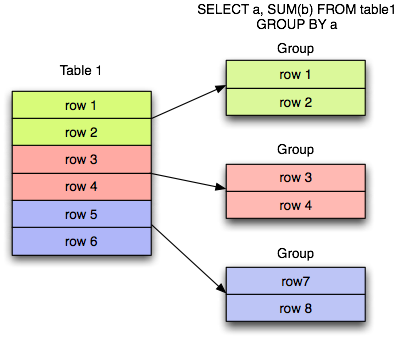
На изображении выше строки разделены на 3 подгруппы по некоему полю «a». Затем применена функция SUM() к полю «b» в каждой из этих групп.
В качестве примера совместного использования агрегации и конструкции GROUP BY рассчитаем количество сотрудников в каждом отделе:
SELECT count(*) FROM employee GROUP BY dep_id| count | dep_id |
|---|---|
| 2 | 1 |
| 10 | 2 |
| 6 | 3 |
| 9 | 4 |
Having¶
Для фильтрации сгруппированных агрегированных значений применяется конструкция HAVING. Например, можно изменить вывод примера выше: отфильтровать отделы, в которых количество сотрудников больше семи:
SELECT count(*) as emp_count FROM employee GROUP BY dep_id HAVING emp_count > 7| count | dep_id |
|---|---|
| 10 | 2 |
| 9 | 4 |
Выборка. Резюме¶
Рассмотрим, как команда SELECT ведёт себя при комбинации всех вышеописанных конструкций.
Для примера возьмём следующий набор строк:
| emp_id | emp_name | dep_id |
|---|---|---|
| 1 | wally | 1 |
| 2 | dilbert | 1 |
| 3 | jack | 2 |
| 4 | ed | 3 |
| 5 | wendy | 1 |
| 6 | dogbert | 4 |
| 7 | boss | 3 |
К которому будет применён вот этот код:
SELECT count(emp_id) as emp_count, dep_id
FROM employee
WHERE dep_id=1 OR dep_id=3 OR dep_id=4
GROUP BY dep_id
HAVING emp_count > 1
ORDER BY emp_count, dep_idКонструкция FROM определяет таблицы, из которых будут выбраны строки. В нашем примере это таблица
employee:... FROM employee ...
emp_id emp_name dep_id 1 wally 1 2 dilbert 1 3 jack 2 4 ed 3 5 wendy 1 6 dogbert 4 7 boss 3 Каждая строка проверяется на соответствие условию, описанному в блоке WHERE. Только строки, прошедшие эту проверку, подвергаются дальнейшей обработке:
... WHERE dep_id=1 OR dep_id=3 OR dep_id=4 ...
emp_id emp_name dep_id 1 wally 1 2 dilbert 1 4 ed 3 5 wendy 1 6 dogbert 4 7 boss 3 Затем производится фоновая группировка по какому-либо критерия с помощью конструкции GROUP BY. Дальнейшая обработка производится уже над этими группами. Для текущего примера это выглядит следующим образом:
... GROUP BY dep_id ...
«group» emp_id emp_name dep_id dep_id=1 1 wally 1 2 dilbert 1 5 wendy 1 dep_id=3 4 ed 3 7 boss 3 dep_id=4 6 dogbert 4 Затем функции агрегации применяются к каждой группе строк. В примере функция
count()применяется к полю emp_id. Это значит, что для группы «1» она получит «1», «2» и «5», в качестве значений. Функцииcount()нет дела до того, какие значения в неё были переданы. И можно для упрощения передать*, что означает «все столбцы». Тем не менее, большинству функций агрегации важно, что именно передаётся в них в качестве параметров. Потому хорошей практикой считается определение тех столбцов, которые передаются в качестве параметров. Результат нашего примера выглядит примерно так:... count(emp_id) AS emp_count ...
emp_count dep_id 3 1 2 3 1 4 Конструкция HAVING работает как WHERE, но только для агрегированных значений. В текущем примере она осуществляет фильтрацию групп, которые имеют более одного сотрудника:
... HAVING emp_count > 1 ...
emp_count dep_id 3 1 2 3 В конце применяется конструкция ORDER BY. Важно помнить, что реляционная математика, заложенная в основу SQL, базируется на понятии множеств. Которые являются по определению неупорядоченными. В обычном случае выборка, агрегация и фильтрация применяются к неупорядоченным строкам. И только в конце, перед отдачей результата пользователю, производится упорядочивание по какому-либо признаку:
... ORDER BY emp_count, dep_id
emp_count dep_id 2 3 3 1
Модель ACID¶
Большинство реляционных баз данных реализует транзакционную модель. Акроним ACID содержит основные принципы такого подхода.
Атомарность (Atomicity)¶
Атомарность гарантирует, что никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни одной. Поскольку на практике невозможно одновременно и атомарно выполнить всю последовательность операций внутри транзакции, вводится понятие «отката» (rollback): если транзакцию не удаётся полностью завершить, результаты всех её до сих пор произведённых действий будут отменены и система вернётся во «внешне исходное» состояние - со стороны будет казаться, что транзакции и не было. Сигнал завершения транзакции называется «фиксация» (commit).
Согласованность (Consistency)¶
Транзакция достигающая своего нормального завершения (EOT - end of transaction, завершение транзакции) и, тем самым, фиксирующая свои результаты, сохраняет согласованность базы данных. Другими словами, каждая успешная транзакция по определению фиксирует только допустимые результаты. Это условие является необходимым для поддержки четвёртого свойства.
Согласованность является более широким понятием. Например, в банковской системе может существовать требование равенства суммы, списываемой с одного счёта, сумме, зачисляемой на другой. Это бизнес-правило и оно не может быть гарантировано только проверками целостности, его должны соблюсти программисты при написании кода транзакций. Если какая-либо транзакция произведёт списание, но не произведёт зачисление, то система останется в некорректном состоянии и свойство согласованности будет нарушено.
Наконец, ещё одно замечание касается того, что в ходе выполнения транзакции согласованность не требуется. В нашем примере, списание и зачисление будут, скорее всего, двумя разными подоперациями и между их выполнением внутри транзакции будет видно несогласованное состояние системы. Однако не нужно забывать, что при выполнении требования изоляции, никаким другим транзакциям эта несогласованность не будет видна. А атомарность гарантирует, что транзакция либо будет полностью завершена, либо ни одна из операций транзакции не будет выполнена. Тем самым эта промежуточная несогласованность является скрытой.
Изолированность (Isolation)¶
Во время выполнения транзакции параллельные транзакции не должны оказывать влияние на её результат. Изолированность - требование дорогое, поэтому в реальных БД существуют различные уровни изоляции.
- Read uncommitted. Низший (нулевой) уровень изоляции. Он гарантирует только отсутствие потерянных обновлений Если несколько параллельных транзакций пытаются изменять одну и ту же строку таблицы, то в окончательном варианте строка будет иметь значение, определенное последней успешно выполненной транзакцией. При этом возможно считывание не только логически несогласованных данных, но и данных, изменения которых ещё не зафиксированы.
- Read committed. На этом уровне обеспечивается защита от чернового, «грязного» чтения, тем не менее, в процессе работы одной транзакции другая может быть успешно завершена и сделанные ею изменения зафиксированы. В итоге первая транзакция будет работать с другим набором данных.
- Repeatable Read. Уровень, при котором читающая транзакция «не видит» данные, которые были изменены но еще не зафиксированы другой транзакцией. При этом никакая другая транзакция не может изменять данные читаемые текущей транзакцией, пока та не окончена.
- Serializable. Самый высокий уровень изолированности; транзакции полностью изолируются друг от друга, каждая выполняется так, как будто параллельных транзакций не существует. Только на этом уровне параллельные транзакции не подвержены эффекту «фантомного чтения» (ситуация, когда при повторном чтении в рамках одной транзакции одна и та же выборка дает разные множества строк).
Надежность (Durability)¶
Независимо от проблем на нижних уровнях (к примеру, обесточивание системы или сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу. Другими словами, если пользователь получил подтверждение от системы, что транзакция выполнена, он может быть уверен, что сделанные им изменения не будут отменены из-за какого-либо сбоя.